

背景
最近老板做横向,然后需要复现一下RLToken,我之前做了hilserl的真机RL,所以就想着改一下hilserl适配RLToken。一开始觉得很简单,无非是把observation从raw的拼接token换成RLToken,但是仔细看了pi0.6的技术报告发现他们RL部分的输出也是actionchunk而不是单步action,所以我就找了一篇25年7月的工作Q-chunking,这篇通讯是Sergey Levine就姑且信任这篇工作了
复现
因为我的工作主要聚焦于真机RL,follow罗剑岚的hilserl及后续工作,主要想优化RLPD使其适配ActionChunk,所以就对比了RLPD/RLPD-AC(使用了action chunk但没有BC约束)/QC三个算法在cube-triple-play-singletask-task2-v0仿真任务上的成功率/训练步数曲线。
下图是我的复现和原作者仓库给出的实验结果比较,整体曲线符合预期
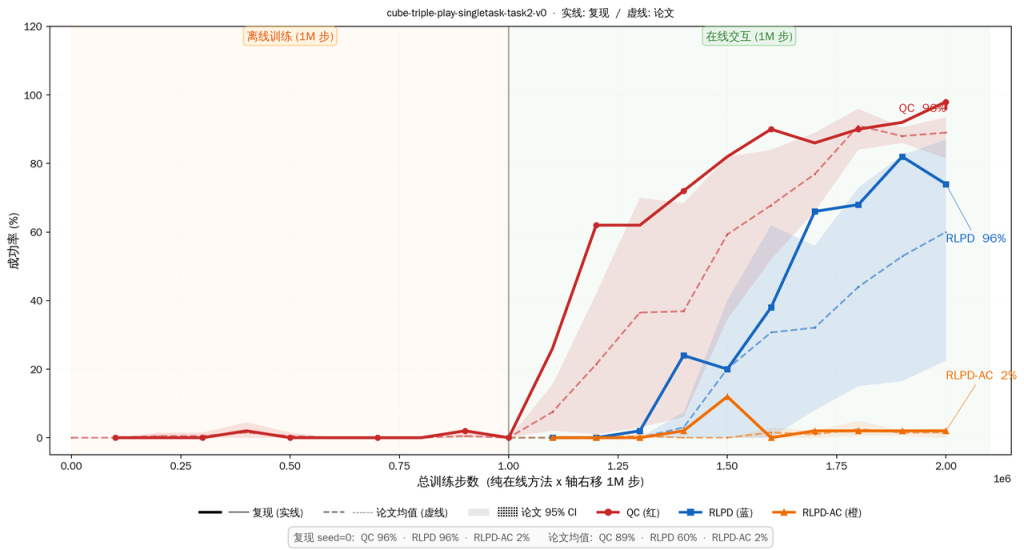
然后我又跑了一下作者给的数据里没有,但是仓库配置里有的一个实验,即QC-RLPD,这个实验相较于RLPD-AC只是多了一个BC约束,让Actor的explore不要偏离offline data太远
哎嘿结果非常的Amazing啊,在1M的online training之后QC-RLPD还是没有提点,和RLPD-AC一样成功率还是0,然后我就跑了10M QC-RLPD看是不是训练时间不够,顺便跑了个10M的RLPD-AC作为对比,结果如下
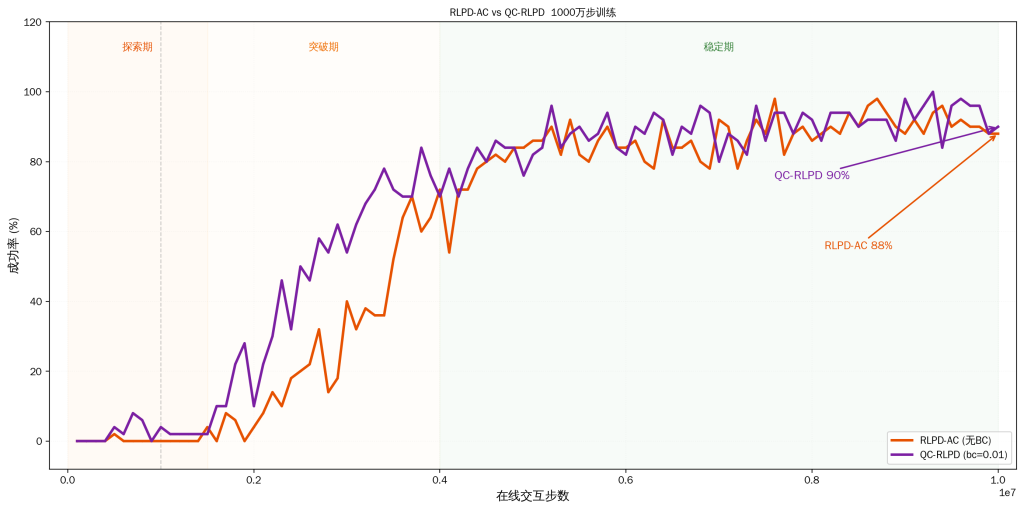
现在的结果就比较符合预期了。RLPD-AC在horizen取5的情况先动作空间扩大5倍,那么收敛所需的online step也增加五倍;而QC-RLPD增加的BC约束虽然有效,但是提点并不是太多,怪不得作者并没有在paper中放出QC-RLPD对应的曲线,想来BC作为是他们的核心改进之一的效果并不好,遂未放
视频
QC(1m offline+1m online)
RLPD(1m online)
RLPD-AC(10m online)
我们可以看
- RLPD很抖,这是单步action RL的固有缺点,因为马尔科夫过程并不会考虑时间轴上游的动作
- RLPD-AC的抖动相对好一点,因为使用了actionchunk优化
- QC的动作最平滑,但是执行时间也是最长的,具体原因我会在下文额度思考章节详细说明
思考
改进方法
QC有几个核心改进,下面简单介绍一下
无偏n-step Q估计
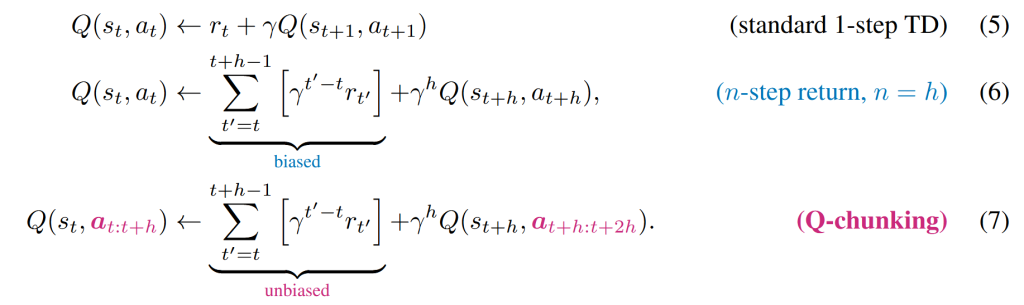
看论文里给出的这几个公式,第一个公式5熟悉RL的读者肯定很熟悉了,这就是标准的时序差分(TD)估计Q值;公式6一样的RL领域也是很常用了,一般叫multi-step TD target,用于加快稀疏奖励传递的,但是会存在奖励偏置(这个笔者其实也不不太明白);公式7就是这篇文章提出的Q-chunking中的Q函数更新公示了,其实就是将$Q(s_t,a_t)$的$a_t$拓展到了action chunk,即$Q(s_t,a_{t:t+h})$,只不过奖励函数还是$r(s_t,a_t)$罢了
我们来看一下QC的核心优化,首先是它的Critic和Actor的Loss定义
这也就说明了为什么QC的执行时间最长了,因为QC的Actor本质上是一个拟合offline data轨迹的IL(imitation learning)模型,explore依赖的是随机噪声导致的小范围扰动,而且这个扰动限定在了offline data的轨迹周围
所以从我的角度来说QC完全不算是Actor/Critic架构,反而更像是DQL那边的value base RL,其作为Actor的Flow model其实就是这两年大热的pi系列魔性中的action expert;从这个角度看的话QC其实是模仿学习路线的算法优化,引入了Critic打分和BFN随机采样
简单来说就是Actor随机采样n个ActionChunk,Critic给这些AC打分,取分最高的为最终决策;而Actor的Loss不包含Q,而是跟随offline data
Comments NOTHING